线上服务咨询
沈阳网站建设哪项技术众所周知 - 汇海网络公司
通过访问与海量数据处理和搜索引擎相关的许多技术,我们经常会看到许多精美的架构图。除了在每个图表表面上叹息图纸的精细度之外,还隐藏了隐藏在架构图背后的设计理念。过去两天我一直在收集大型网站的架构设计图纸。为了享受各种大型网站架构设计的兴奋,第二个也可用于休闲时间和排练。为什么不?在此,总结如外国维基百科,Facebook,雅虎!YouTube,MySpace,Twitter,国内技术如优酷等大型网站技术架构(本文重点介绍优酷的技术架构),给读者。本文重点介绍每张图片的亮点及其背后的含义,同时简化了图的说明文字。好的,享受这个建筑盛宴。当然,如果您有任何建议或疑问,请不要犹豫,纠正我。谢谢。 1. WikiPedia技术架构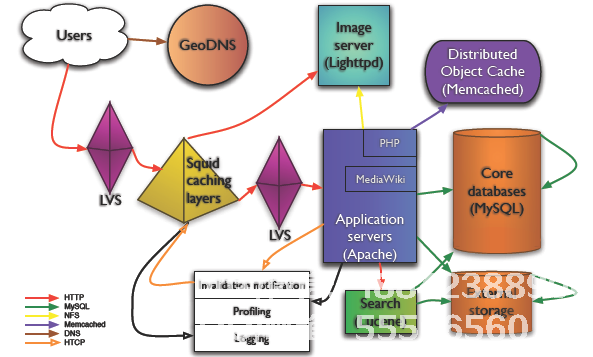 WikiPedia技术架构从维基百科复制@Mark Bergsma数据:峰值每秒30,000次HTTP请求每秒3Gbit流量,近375MB350台PC服务器。 GeoDNSA:BIND的40行补丁,为BIND'中的现有视图添加地理过滤器支持,将用户带到附近的服务器。 GeoDNS在WikiPedia架构中的角色当然取决于WikiPedia内容的性质 - 适用于每个国家和地区。负载均衡:LVS,请参见下图:
WikiPedia技术架构从维基百科复制@Mark Bergsma数据:峰值每秒30,000次HTTP请求每秒3Gbit流量,近375MB350台PC服务器。 GeoDNSA:BIND的40行补丁,为BIND'中的现有视图添加地理过滤器支持,将用户带到附近的服务器。 GeoDNS在WikiPedia架构中的角色当然取决于WikiPedia内容的性质 - 适用于每个国家和地区。负载均衡:LVS,请参见下图: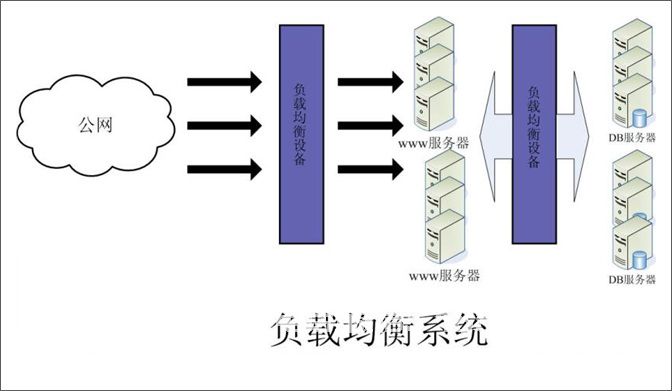 。
2,Facebook架构
。
2,Facebook架构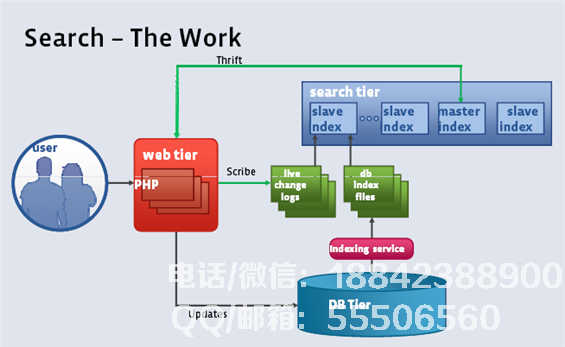 Facebook搜索功能架构图细心的读者将能够发现本文中出现的上层子架构:从几个架构图中窃取一点航海数据处理经验。本文与前一篇文章的区别在于前几篇文章中只有少数几篇。这个系列将有数百个架构图供您欣赏。 3.雅虎!邮件架构
Facebook搜索功能架构图细心的读者将能够发现本文中出现的上层子架构:从几个架构图中窃取一点航海数据处理经验。本文与前一篇文章的区别在于前几篇文章中只有少数几篇。这个系列将有数百个架构图供您欣赏。 3.雅虎!邮件架构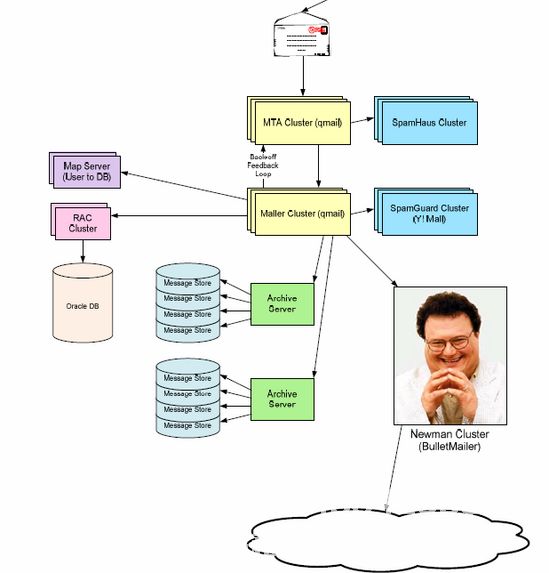 Yahoo!邮件架构雅虎!邮件体系结构部署Oracle RAC以存储与邮件服务相关的元数据。 4,twitter技术架构
Yahoo!邮件架构雅虎!邮件体系结构部署Oracle RAC以存储与邮件服务相关的元数据。 4,twitter技术架构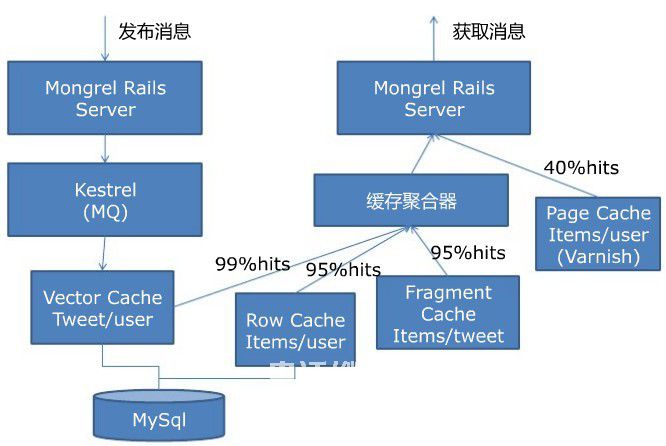 twitter整体架构设计图Twitter平台大致由twitter.com,手机和第三方应用组成,如下图所示(其中流量主要基于手机和第三方):
twitter整体架构设计图Twitter平台大致由twitter.com,手机和第三方应用组成,如下图所示(其中流量主要基于手机和第三方):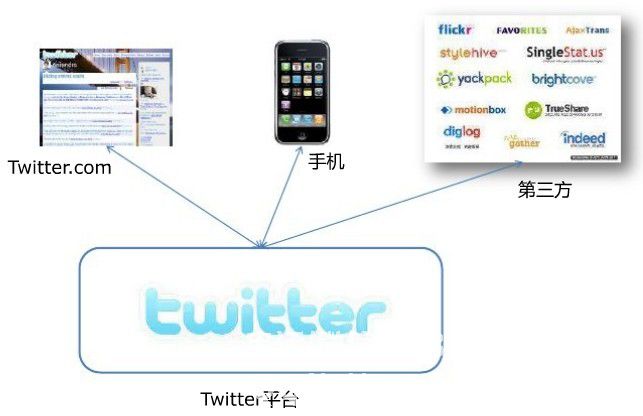 缓存大web该项目发挥了关键作用,因为数据更接近CPU并且速度越快。下图是缓存缓存图:
缓存大web该项目发挥了关键作用,因为数据更接近CPU并且速度越快。下图是缓存缓存图: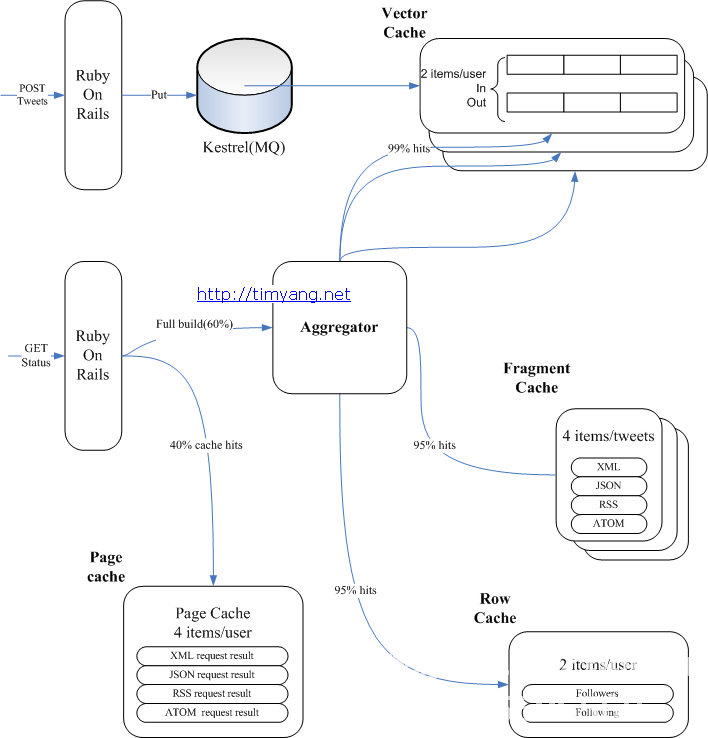 关于缓存系统,您还可以查看下图:
关于缓存系统,您还可以查看下图: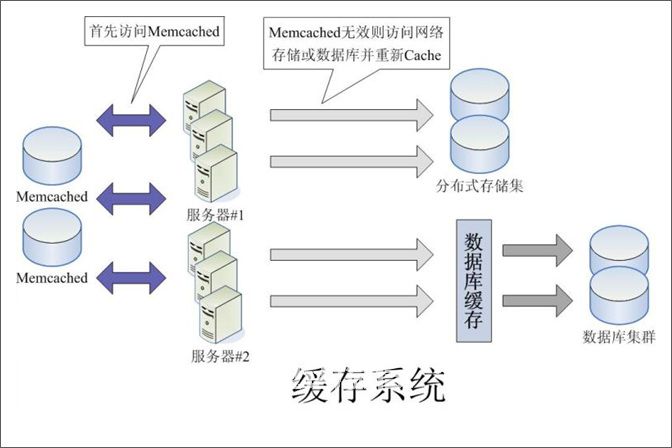 5,Google App Engine技术架构
5,Google App Engine技术架构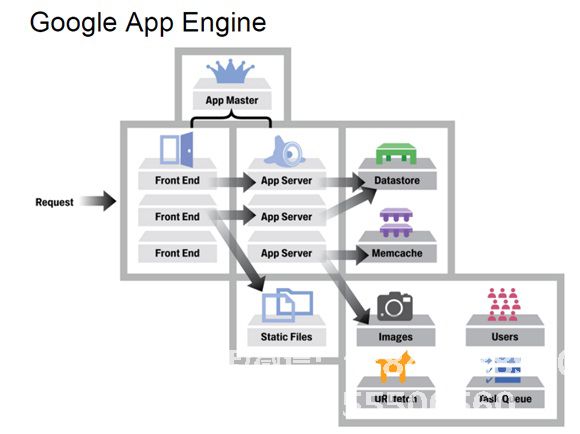 GAE架构图简单来说,上面的GAE架构如图所示分为三部分:前端,数据存储区和服务组。前端由4个模块组成:前端,静态文件,App Server,App Master。 Datastore是一个基于BigTable技术的分布式数据库。虽然它也可以理解为服务,但它是App Engine中的一个非常核心的模块,因为它是整个App Engine存储持久数据的地方。具体细节将在下一节中讨论。
整个服务组包括许多App Server调用服务,例如Memcache,图形,用户,URL爬网和任务队列。 6,亚马逊技术架构
GAE架构图简单来说,上面的GAE架构如图所示分为三部分:前端,数据存储区和服务组。前端由4个模块组成:前端,静态文件,App Server,App Master。 Datastore是一个基于BigTable技术的分布式数据库。虽然它也可以理解为服务,但它是App Engine中的一个非常核心的模块,因为它是整个App Engine存储持久数据的地方。具体细节将在下一节中讨论。
整个服务组包括许多App Server调用服务,例如Memcache,图形,用户,URL爬网和任务队列。 6,亚马逊技术架构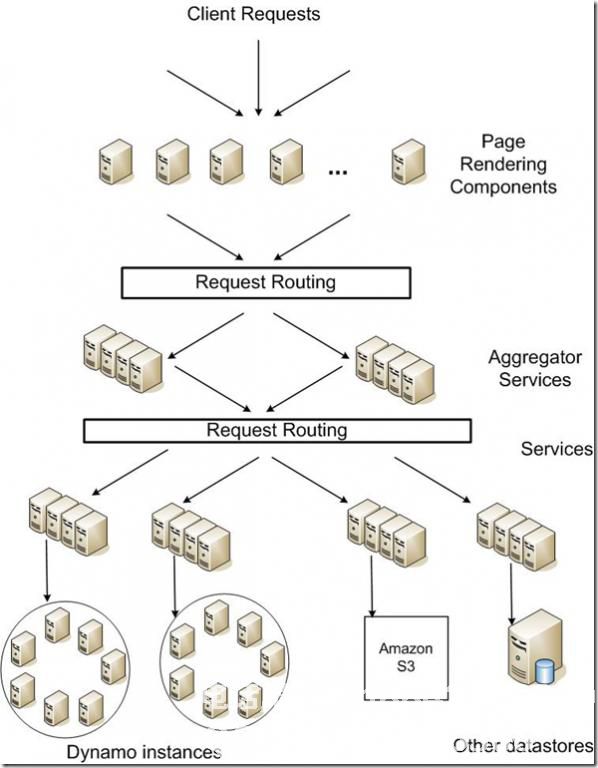 亚马逊的Dynamo Key-Value存储架构图可能是亚马逊不熟悉的读者,它现在是全球最大的各种在线零售商和全球第二大互联网公司。之前它只是一个小型的在线书店。好的,我们来看看它的架构。 Dynamo是亚马逊的键值模式存储平台,具有良好的可用性和可扩展性以及良好的性能:99.9%的读写访问响应时间在300ms内。数据根据分布式系统中常用的散列算法进行划分,并放置在不同的节点上。当执行读取操作时,它还基于密钥的哈希值搜索相应的节点。 Dynamo使用Consistent Hashing算法。该节点对应于某个散列值,但是对应于散列值范围。如果密钥散列值落在此范围内,则沿着环顺时针找到它。需要。 Dynamo对Consistent Hashing算法的改进是它将环上的一组机器作为节点(而不是memcached作为节点)。这组机器通过同步机制保证数据的一致性。
下图是分布式存储系统的示意图,读者可以观察到它:
亚马逊的Dynamo Key-Value存储架构图可能是亚马逊不熟悉的读者,它现在是全球最大的各种在线零售商和全球第二大互联网公司。之前它只是一个小型的在线书店。好的,我们来看看它的架构。 Dynamo是亚马逊的键值模式存储平台,具有良好的可用性和可扩展性以及良好的性能:99.9%的读写访问响应时间在300ms内。数据根据分布式系统中常用的散列算法进行划分,并放置在不同的节点上。当执行读取操作时,它还基于密钥的哈希值搜索相应的节点。 Dynamo使用Consistent Hashing算法。该节点对应于某个散列值,但是对应于散列值范围。如果密钥散列值落在此范围内,则沿着环顺时针找到它。需要。 Dynamo对Consistent Hashing算法的改进是它将环上的一组机器作为节点(而不是memcached作为节点)。这组机器通过同步机制保证数据的一致性。
下图是分布式存储系统的示意图,读者可以观察到它: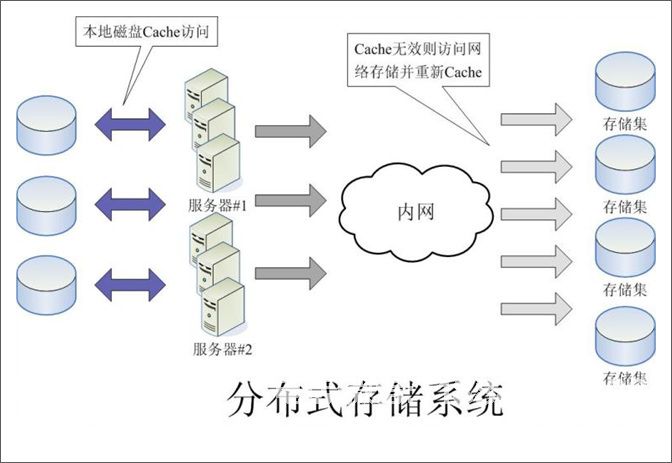 亚马逊的云架构如下:
亚马逊的云架构如下: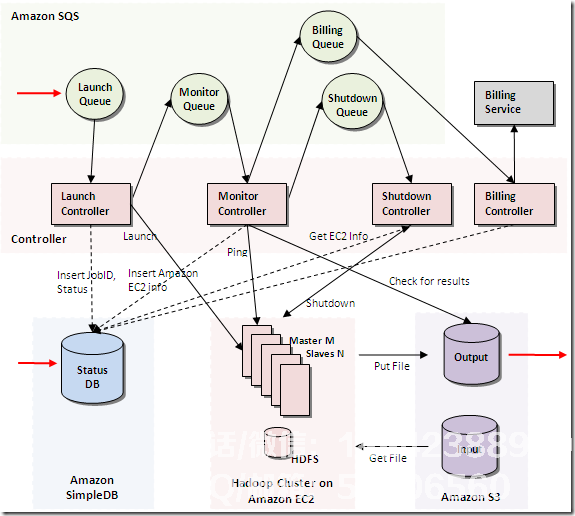 亚马逊的云架构图7,优酷的技术架构从一开始,优酷已经建立了一个CMS解决方案 - 结束页面显示,模块之间的分离比较合适,前端的可扩展性非常好,UI的分离,使得开发和维护变得非常简单灵活,下图是优酷前端的模块调用关系 - 结束:
亚马逊的云架构图7,优酷的技术架构从一开始,优酷已经建立了一个CMS解决方案 - 结束页面显示,模块之间的分离比较合适,前端的可扩展性非常好,UI的分离,使得开发和维护变得非常简单灵活,下图是优酷前端的模块调用关系 - 结束: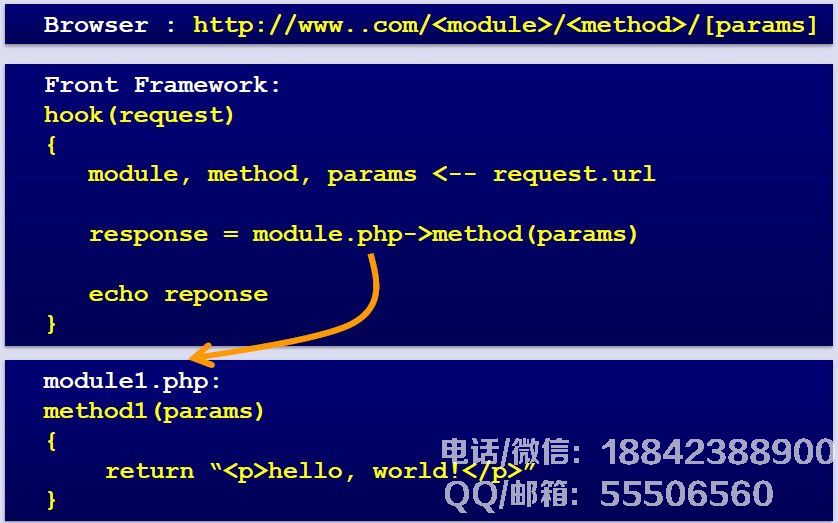 基于模块,方法和参数确定相对独立的模块非常简单。下图显示优酷的前端部分架构:
基于模块,方法和参数确定相对独立的模块非常简单。下图显示优酷的前端部分架构: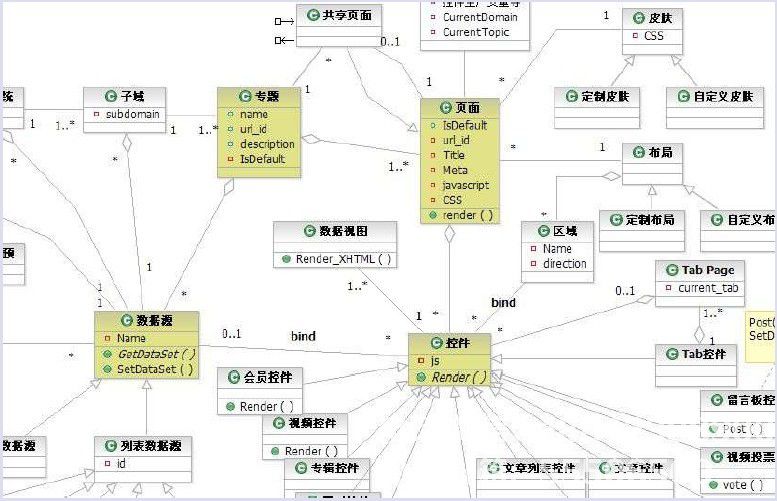 优酷的数据库架构也经历了许多曲折,从单个MySQL服务器(Just Running)开始到简单的MySQL主从复制,SSD优化,垂直库,水平分片子库。简单的MySQL主从复制。 MySQL主从复制解决了数据库的读写分离问题,提高了读取性能。原始图片如下:
优酷的数据库架构也经历了许多曲折,从单个MySQL服务器(Just Running)开始到简单的MySQL主从复制,SSD优化,垂直库,水平分片子库。简单的MySQL主从复制。 MySQL主从复制解决了数据库的读写分离问题,提高了读取性能。原始图片如下: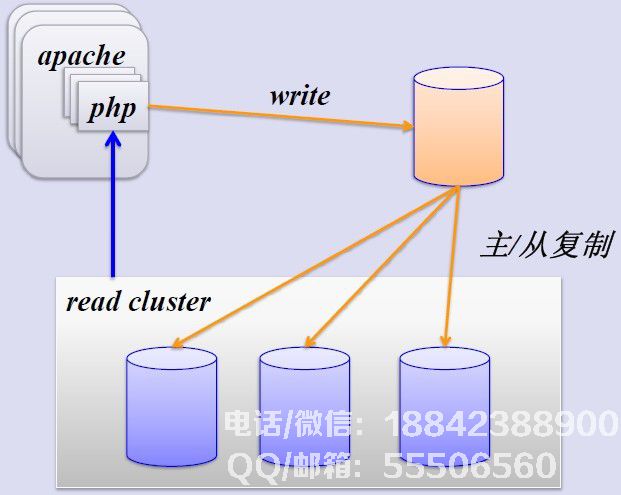 主从复制的过程如下:
主从复制的过程如下: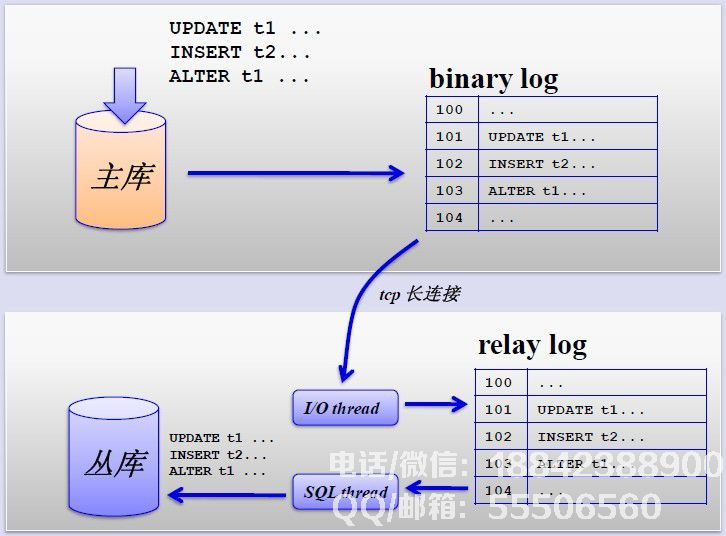 然而,主从复制也带来了其他一系列性能瓶颈:写入无法扩展写入无法缓存复制延迟锁定表率增加表变大,缓存率降低,问题将永远得到解决,从而产生以下优化方案。 MySQL垂直分区如果业务被独立切割,将不同的业务数据放入不同的数据库服务器是个好主意,如果其中一个服务崩溃,它不会影响其他服务的正常运行,也会影响它负载分流的作用,大大提高了数据库的吞吐量。
垂直分区后的数据库模式如下:
然而,主从复制也带来了其他一系列性能瓶颈:写入无法扩展写入无法缓存复制延迟锁定表率增加表变大,缓存率降低,问题将永远得到解决,从而产生以下优化方案。 MySQL垂直分区如果业务被独立切割,将不同的业务数据放入不同的数据库服务器是个好主意,如果其中一个服务崩溃,它不会影响其他服务的正常运行,也会影响它负载分流的作用,大大提高了数据库的吞吐量。
垂直分区后的数据库模式如下: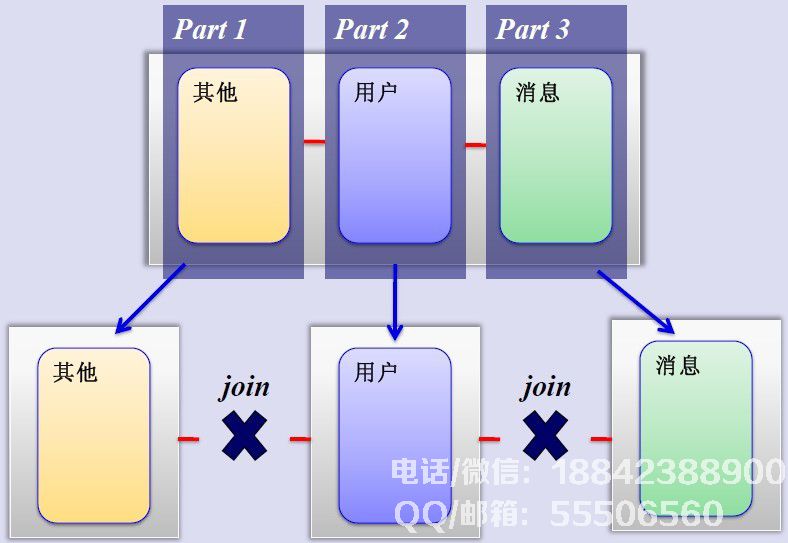 但是,虽然服务彼此之间足够独立,但某些服务总是或多或少地连接起来,例如用户,基本上与每个业务相关联,而这种分区方法可以解决单表数据暴涨的问题,为什么不尝试水平分片? MySQL水平分片(Sharding)这是一个非常好的主意,分组用户按照一定的规则(通过id hash),并将用户组的数据存储到数据库分片中,即分片,所以作为数量用户增加,只需配置服务器。原理图如下:
但是,虽然服务彼此之间足够独立,但某些服务总是或多或少地连接起来,例如用户,基本上与每个业务相关联,而这种分区方法可以解决单表数据暴涨的问题,为什么不尝试水平分片? MySQL水平分片(Sharding)这是一个非常好的主意,分组用户按照一定的规则(通过id hash),并将用户组的数据存储到数据库分片中,即分片,所以作为数量用户增加,只需配置服务器。原理图如下: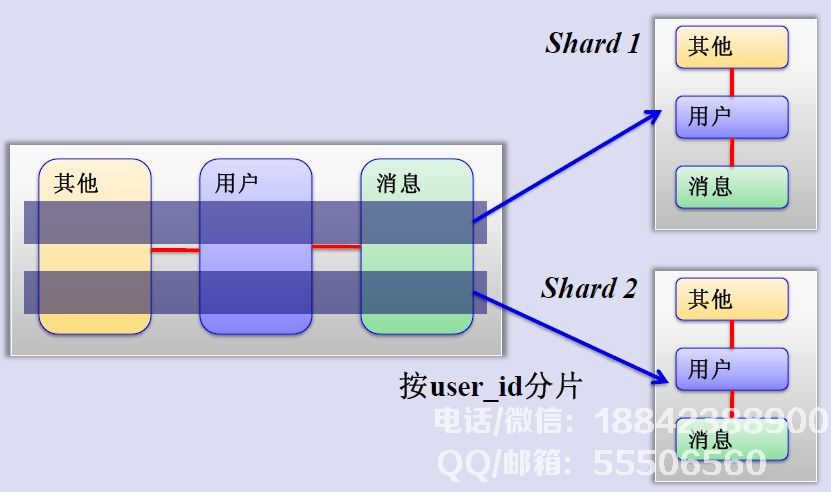 如何确定用户的分片,可以创建与用户和分片对应的数据表。找到用户的分片ID,然后从相应的分片查询相关数据,如下所示:
如何确定用户的分片,可以创建与用户和分片对应的数据表。找到用户的分片ID,然后从相应的分片查询相关数据,如下所示: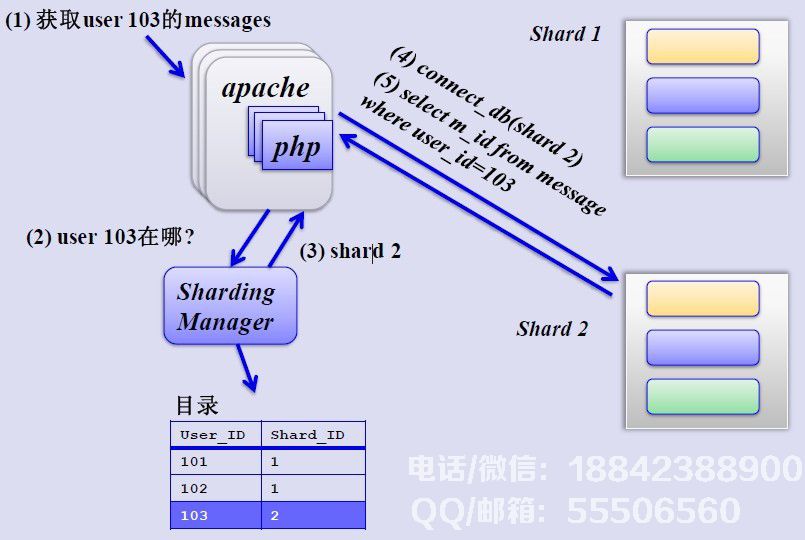 然而,优酷如何解决交叉分片查询?这是一个难点。根据介绍,优酷试图不跨越分片查询。对于多维碎片索引和分布式搜索引擎,缺点是分布式数据库查询(这非常麻烦并且消耗性能)。缓存策略看起来像一个大系统对“缓存”有一个情有独钟,从http缓存到memcached内存数据缓存,但优酷表示没有内存缓存,原因如下:避免内存复制,避免内存锁,如果您收到来自大哥的通知删除视频,如果缓存中很麻烦并且Squid的write()用户进程空间被占用,则Lighttpd 1.5的AIO(异步I/O)将文件读取到用户内存并且更少高效。
但是为什么我们访问优酷会如此顺利,相比土豆,优酷的视频加载速度稍好一些?这要归功于优酷建立的完善的内容分发网络(CDN)。它保证位于该国不同位置的用户进行近距离访问。——用户点击视频请求,优酷将根据用户的位置。靠近用户并具有众所周知的服务状态的视频服务器地址被发送给用户,从而确保用户可以获得快速的视频体验。这是CDN带来的优势,而且它已经接近了。
然而,优酷如何解决交叉分片查询?这是一个难点。根据介绍,优酷试图不跨越分片查询。对于多维碎片索引和分布式搜索引擎,缺点是分布式数据库查询(这非常麻烦并且消耗性能)。缓存策略看起来像一个大系统对“缓存”有一个情有独钟,从http缓存到memcached内存数据缓存,但优酷表示没有内存缓存,原因如下:避免内存复制,避免内存锁,如果您收到来自大哥的通知删除视频,如果缓存中很麻烦并且Squid的write()用户进程空间被占用,则Lighttpd 1.5的AIO(异步I/O)将文件读取到用户内存并且更少高效。
但是为什么我们访问优酷会如此顺利,相比土豆,优酷的视频加载速度稍好一些?这要归功于优酷建立的完善的内容分发网络(CDN)。它保证位于该国不同位置的用户进行近距离访问。——用户点击视频请求,优酷将根据用户的位置。靠近用户并具有众所周知的服务状态的视频服务器地址被发送给用户,从而确保用户可以获得快速的视频体验。这是CDN带来的优势,而且它已经接近了。
WikiPedia技术架构从维基百科复制@Mark Bergsma数据:峰值每秒30,000次HTTP请求每秒3Gbit流量,近375MB350台PC服务器。 GeoDNSA:BIND的40行补丁,为BIND'中的现有视图添加地理过滤器支持,将用户带到附近的服务器。 GeoDNS在WikiPedia架构中的角色当然取决于WikiPedia内容的性质 - 适用于每个国家和地区。负载均衡:LVS,请参见下图:。
2,Facebook架构 Facebook搜索功能架构图细心的读者将能够发现本文中出现的上层子架构:从几个架构图中窃取一点航海数据处理经验。本文与前一篇文章的区别在于前几篇文章中只有少数几篇。这个系列将有数百个架构图供您欣赏。 3.雅虎!邮件架构 Yahoo!邮件架构雅虎!邮件体系结构部署Oracle RAC以存储与邮件服务相关的元数据。 4,twitter技术架构 twitter整体架构设计图Twitter平台大致由twitter.com,手机和第三方应用组成,如下图所示(其中流量主要基于手机和第三方):缓存大web该项目发挥了关键作用,因为数据更接近CPU并且速度越快。下图是缓存缓存图:关于缓存系统,您还可以查看下图: 5,Google App Engine技术架构 GAE架构图简单来说,上面的GAE架构如图所示分为三部分:前端,数据存储区和服务组。前端由4个模块组成:前端,静态文件,App Server,App Master。 Datastore是一个基于BigTable技术的分布式数据库。虽然它也可以理解为服务,但它是App Engine中的一个非常核心的模块,因为它是整个App Engine存储持久数据的地方。具体细节将在下一节中讨论。
整个服务组包括许多App Server调用服务,例如Memcache,图形,用户,URL爬网和任务队列。 6,亚马逊技术架构亚马逊的Dynamo Key-Value存储架构图可能是亚马逊不熟悉的读者,它现在是全球最大的各种在线零售商和全球第二大互联网公司。之前它只是一个小型的在线书店。好的,我们来看看它的架构。 Dynamo是亚马逊的键值模式存储平台,具有良好的可用性和可扩展性以及良好的性能:99.9%的读写访问响应时间在300ms内。数据根据分布式系统中常用的散列算法进行划分,并放置在不同的节点上。当执行读取操作时,它还基于密钥的哈希值搜索相应的节点。 Dynamo使用Consistent Hashing算法。该节点对应于某个散列值,但是对应于散列值范围。如果密钥散列值落在此范围内,则沿着环顺时针找到它。需要。 Dynamo对Consistent Hashing算法的改进是它将环上的一组机器作为节点(而不是memcached作为节点)。这组机器通过同步机制保证数据的一致性。
下图是分布式存储系统的示意图,读者可以观察到它:亚马逊的云架构如下:亚马逊的云架构图7,优酷的技术架构从一开始,优酷已经建立了一个CMS解决方案 - 结束页面显示,模块之间的分离比较合适,前端的可扩展性非常好,UI的分离,使得开发和维护变得非常简单灵活,下图是优酷前端的模块调用关系 - 结束:基于模块,方法和参数确定相对独立的模块非常简单。下图显示优酷的前端部分架构:优酷的数据库架构也经历了许多曲折,从单个MySQL服务器(Just Running)开始到简单的MySQL主从复制,SSD优化,垂直库,水平分片子库。简单的MySQL主从复制。 MySQL主从复制解决了数据库的读写分离问题,提高了读取性能。原始图片如下:主从复制的过程如下:然而,主从复制也带来了其他一系列性能瓶颈:写入无法扩展写入无法缓存复制延迟锁定表率增加表变大,缓存率降低,问题将永远得到解决,从而产生以下优化方案。 MySQL垂直分区如果业务被独立切割,将不同的业务数据放入不同的数据库服务器是个好主意,如果其中一个服务崩溃,它不会影响其他服务的正常运行,也会影响它负载分流的作用,大大提高了数据库的吞吐量。
垂直分区后的数据库模式如下:但是,虽然服务彼此之间足够独立,但某些服务总是或多或少地连接起来,例如用户,基本上与每个业务相关联,而这种分区方法可以解决单表数据暴涨的问题,为什么不尝试水平分片? MySQL水平分片(Sharding)这是一个非常好的主意,分组用户按照一定的规则(通过id hash),并将用户组的数据存储到数据库分片中,即分片,所以作为数量用户增加,只需配置服务器。原理图如下:如何确定用户的分片,可以创建与用户和分片对应的数据表。找到用户的分片ID,然后从相应的分片查询相关数据,如下所示:然而,优酷如何解决交叉分片查询?这是一个难点。根据介绍,优酷试图不跨越分片查询。对于多维碎片索引和分布式搜索引擎,缺点是分布式数据库查询(这非常麻烦并且消耗性能)。缓存策略看起来像一个大系统对“缓存”有一个情有独钟,从http缓存到memcached内存数据缓存,但优酷表示没有内存缓存,原因如下:避免内存复制,避免内存锁,如果您收到来自大哥的通知删除视频,如果缓存中很麻烦并且Squid的write()用户进程空间被占用,则Lighttpd 1.5的AIO(异步I/O)将文件读取到用户内存并且更少高效。
但是为什么我们访问优酷会如此顺利,相比土豆,优酷的视频加载速度稍好一些?这要归功于优酷建立的完善的内容分发网络(CDN)。它保证位于该国不同位置的用户进行近距离访问。——用户点击视频请求,优酷将根据用户的位置。靠近用户并具有众所周知的服务状态的视频服务器地址被发送给用户,从而确保用户可以获得快速的视频体验。这是CDN带来的优势,而且它已经接近了。
网站建设,沈阳网站建设,沈阳网络公司,沈阳网站设计,沈阳网站制作
